AI in Data Engineering: Building Reliable Data Systems at Scale

AI is transforming data engineering. Coding agents can now generate SQL transformations, configure connectors, and define API schemas in minutes rather than days. But here's the catch: a query that works perfectly on test data may fail catastrophically when confronted with late-arriving events, schema evolution, or terabyte-scale volumes.
How do we ensure that AI-generated data systems meet the rigorous non-functional requirements that production data platforms demand? This article presents our framework for integrating AI coding agents into data engineering workflows while maintaining data quality, reliability, governance, and trust.
The Scaling Challenge
Organizations are targeting 3-5x productivity improvements through AI-assisted development. The velocity is real, but it creates an unsustainable burden on traditional data engineering practices:
- Manual code review can't scale when agents generate dozens of pipeline changes daily
- Ad-hoc data quality checks miss subtle issues that only manifest at scale or over time
- Tribal knowledge about production constraints doesn't transfer to AI agents
- Integration testing becomes a bottleneck when deployment velocity outpaces validation capacity
- Operations and troubleshooting overwhelm teams when they have to manage dozens of pipelines in production
The fundamental problem is coding agents optimize for functional correctness (e.g. does the query return the right results?) while production data systems require a much broader set of guarantees.
Without systematic guardrails, AI-generated data pipelines work in demos but fail in production and overwhelm the data engineering teams that have to fill the gaps.
A Data Quality Governance Framework
Successfully integrating AI into data engineering requires a governance framework that addresses three dimensions: transparency, validation, and operations.
Transparency: Exposing Data Lineage and Reasoning
AI agents need to operate within systems that expose their reasoning and the data flows they create. This serves two purposes: enabling human oversight and providing feedback for iterative refinement.
What does transparency look like for data engineering?
- Clear Transformations: Well-defined data transformations that make it obvious what was transformed and why
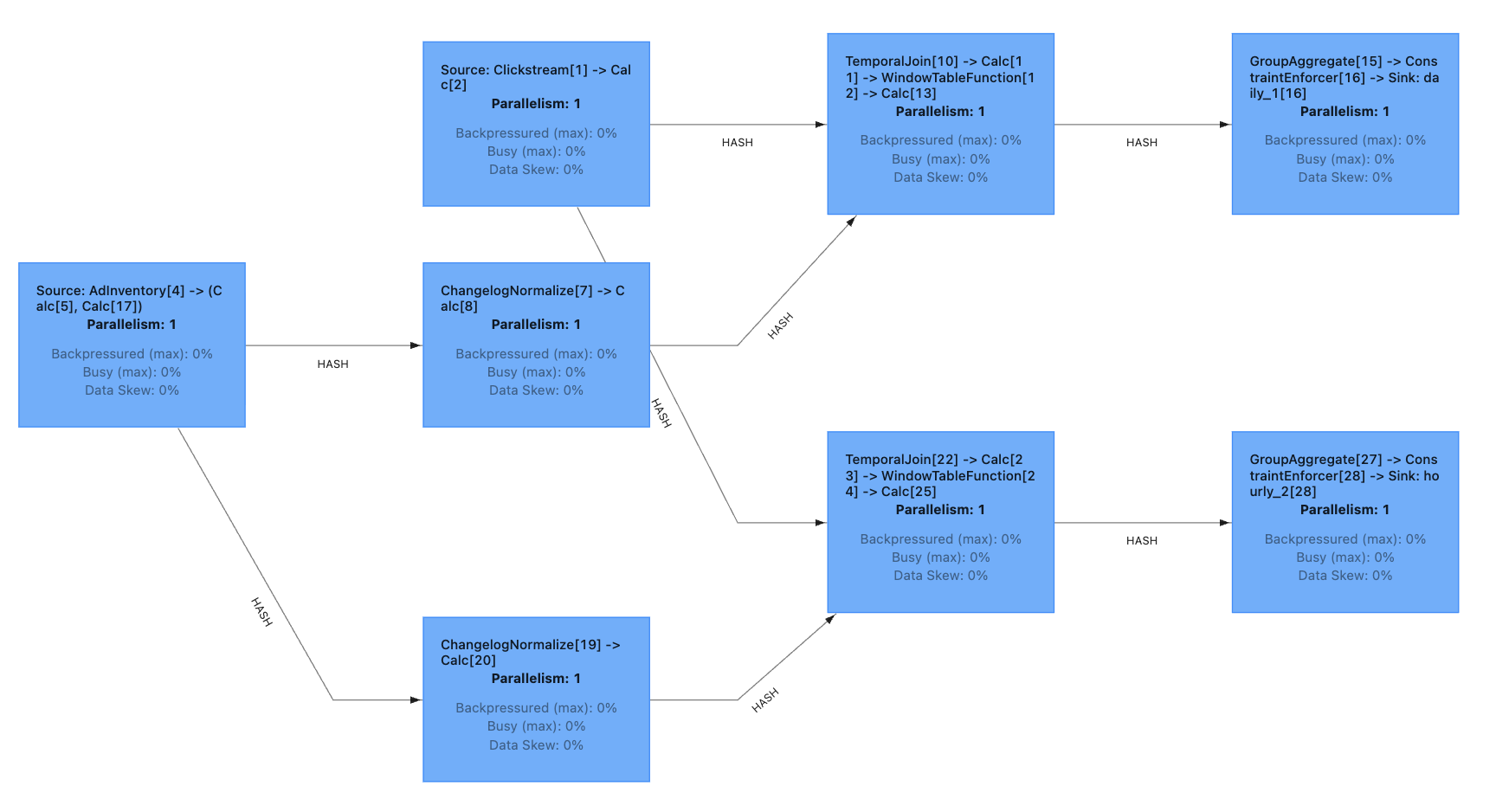
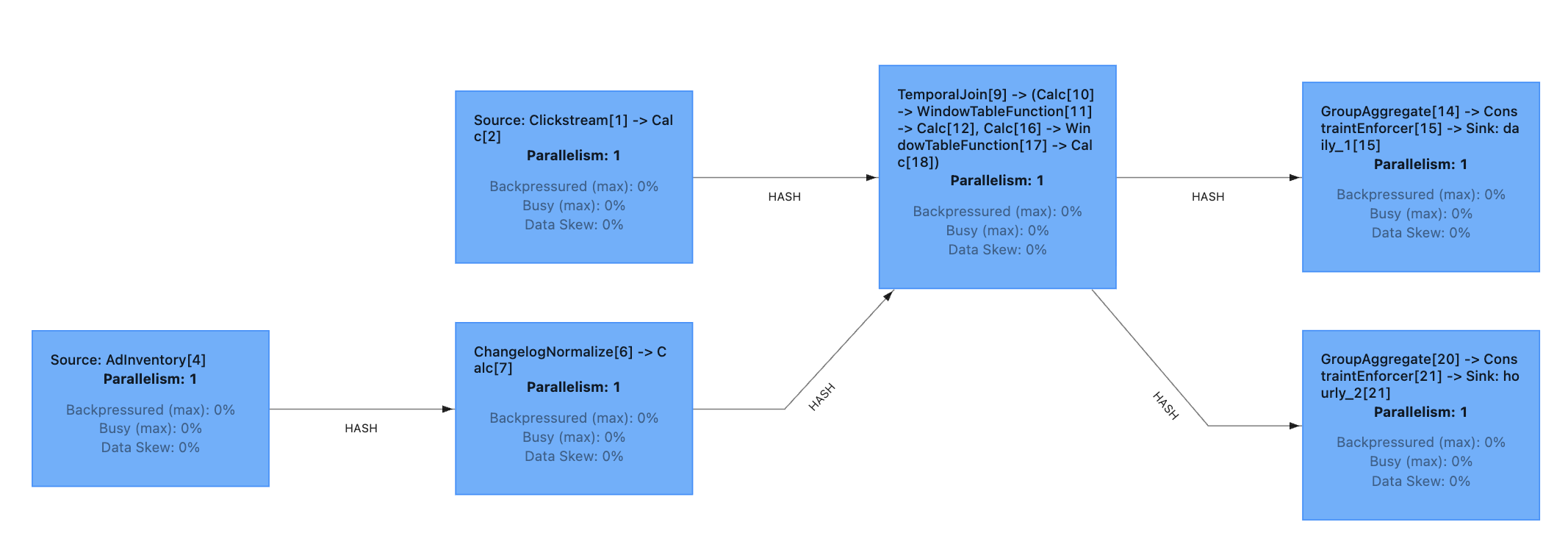
- Data lineage tracking: Trace every output field back through transformations to source systems
- Computational DAGs: Visualize how data flows from ingestion through processing to serving
- Schema inference: Make explicit the types, keys, and timestamps the agent has assumed
- Execution plans: Show which engines execute which computations
When an agent proposes a data pipeline, we should see not just the SQL code but the complete picture: where data originates, how it transforms, what guarantees apply at each stage, and how it ultimately reaches consumers.
=== SpendingTransactions
ID: default_catalog.default_database.SpendingTransactions
Type: stream
Stage: flink
Inputs: Transactions, Accounts, AccountHolders
Annotations:
- temporal-join: uses event-time semantics
- stream-root: Transactions
Primary Key: transactionId, tx_time
Timestamp : tx_time
Schema:
- transactionId: BIGINT NOT NULL
- amount: DECIMAL(10,2) NOT NULL
- tx_time: TIMESTAMP_LTZ(3) *ROWTIME* NOT NULL
- creditor_name: VARCHAR NOT NULL
This representation combines inferences from the logical layer (primary keys, timestamps) with physical mappings (execution stage, inputs) to give us complete visibility into agent-generated pipelines.
Validation: Real-Time Quality Assessment
Every agent action must pass through validation layers that assess correctness before execution. Here's what makes data pipelines different from application code: bugs often produce silently wrong results: queries that execute successfully but return incorrect data.
Effective validation operates at multiple levels:
Logical Validation
- Syntax and schema verification
- Data type inference and consistency checking
- Primary key and timestamp propagation validation
- Table type verification (stream vs. state semantics)
Physical Validation
- Engine capability matching (can Postgres execute this temporal join?)
- Data type mapping consistency across engines
- Connector configuration verification
- Topological constraint satisfaction (data must reach database before API can serve it)
Semantic Validation
- Business rule assertions
- Data quality constraints (nullability, referential integrity, value ranges)
- SLA verification (latency bounds, freshness guarantees)
The validation system needs to provide actionable feedback when checks fail. Rather than cryptic error messages, agents need comprehensive context and suggested fixes:
ERROR: Temporal join requires timestamp column on probe side
Table 'Transactions' is used in a temporal join with 'Accounts'
but lacks a rowtime attribute.
Suggestion: Add a timestamp column with WATERMARK definition:
tx_time TIMESTAMP_LTZ(3),
WATERMARK FOR tx_time AS tx_time - INTERVAL '5' SECOND
Operations: Continuous Monitoring and Autonomous Troubleshooting
Building pipelines is only half the challenge. When you're managing dozens of AI-generated data pipelines in production, operations becomes the bottleneck. Traditional monitoring approaches (dashboards, manual alerts, runbooks) can't scale when pipeline count grows faster than team headcount.
The framework needs to support autonomous operations:
Continuous Monitoring
- Real-time data quality assertions that validate business rules on every record
- SLA tracking that measures end-to-end latency from source event to API availability
- Schema drift detection that catches upstream changes before they break downstream consumers
- Resource utilization monitoring that identifies capacity issues before they cause failures
Autonomous Troubleshooting
- Automatic correlation of symptoms to root causes using lineage information
- Self-healing for common failure modes (connector reconnection, checkpoint recovery, partition rebalancing)
- Intelligent alerting that groups related issues and suppresses noise
- Runbook automation that executes standard remediation steps without human intervention
Observability Integration
- Structured logging that links every record to its source transformation
- Distributed tracing across the complete pipeline (Kafka → Flink → Postgres → API)
- Metrics export to existing observability platforms (Prometheus, Datadog, CloudWatch)
The goal is a team of three data engineers being able to operate dozens pipelines in production. That's only possible when the harness handles routine operations autonomously and escalates only the issues that genuinely require human judgment.
Capturing Data Engineering Expertise
The effectiveness of AI in data engineering depends on systematically capturing and encoding human expertise. This falls into three categories: domain knowledge, operational patterns, and failure modes.
Domain Knowledge Encoding
Data engineers carry implicit knowledge about their data domains: which fields contain PII, how upstream systems behave during maintenance windows, what query patterns consumers actually use. This knowledge needs to be made explicit for agents to leverage.
What works:
- Schema annotations: Capture business semantics beyond technical types
- Data contracts: Formalize expectations between producers and consumers
- Quality rules: Encode domain-specific validity constraints
- Access patterns: Document how data gets queried in practice
-- Domain knowledge encoded in table definition
/** Customer spending transactions enriched with merchant details.
PII: contains customer_id (indirect identifier)
Freshness SLA: < 5 minutes from source event
Primary consumer: Fraud detection system (latency-sensitive)
*/
SpendingTransactions := SELECT ...
Operational Pattern Libraries
Production data pipelines exhibit recurring patterns: CDC deduplication, temporal enrichment joins, windowed aggregations, slowly changing dimensions. We encode them as reusable patterns to reduce the occurrence of subtle bugs when agents try to recreate them.
-- Pattern: CDC deduplication to current state
Accounts := DISTINCT AccountsCDC ON account_id ORDER BY update_time DESC;
-- Pattern: Temporal enrichment join
EnrichedTransactions := SELECT t.*, a.account_type
FROM Transactions t
JOIN Accounts FOR SYSTEM_TIME AS OF t.tx_time a
ON t.account_id = a.account_id;
-- Pattern: Tumbling window aggregation
HourlyMetrics := SELECT
window_start, COUNT(*) as event_count
FROM TABLE(TUMBLE(TABLE Events, DESCRIPTOR(event_time), INTERVAL '1' HOUR))
GROUP BY window_start;
These patterns encode not just the SQL syntax but the semantic intent and operational characteristics. When an agent needs CDC deduplication, it applies the established pattern rather than improvising a potentially incorrect solution.
Failure Mode Documentation
Every production incident represents encoded knowledge about what can go wrong. Systematically capturing failure modes and their resolutions creates a corpus that agents can learn from:
- Symptoms: How the failure manifested (data delays, incorrect aggregates, schema mismatches)
- Root cause: The underlying issue (late data handling, join key mismatch, type coercion)
- Resolution: How we fixed it
- Prevention: What validation or pattern would have caught this earlier
Over time, this corpus enables agents to anticipate failure modes and proactively avoid them.
The Data Engineering Harness
Implementing governance, validation, and expertise capture requires purpose-built infrastructure. We call this a data engineering harness: a system that provides the guardrails and feedback loops coding agents need to produce production-grade data systems.
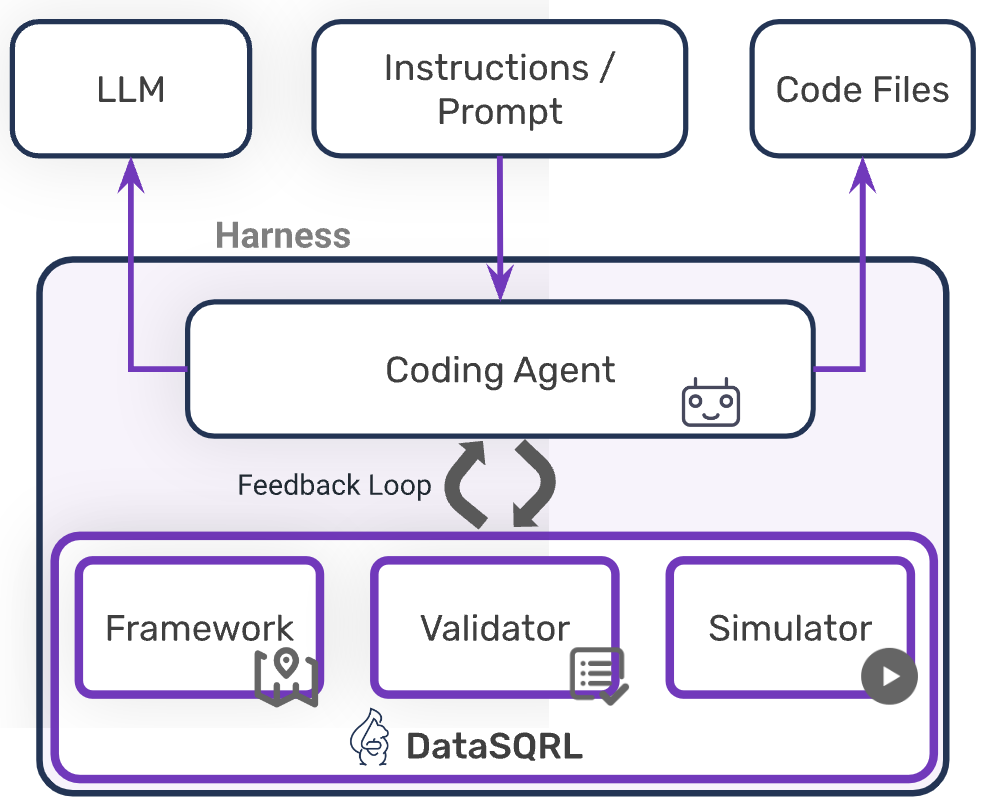
The harness has three integrated components:
Conceptual Framework
The framework provides a precise vocabulary for reasoning about data transformations:
Logical Layer: Expresses what transformations are needed using SQL extended with stream processing semantics. The declarative nature enables deep introspection. We can analyze query structure, infer schemas, and validate semantics.
Physical Layer: Represents how data gets processed through engine assignment and configuration. A cost-based optimizer maps logical operations to physical engines (Flink, Kafka, Postgres, Iceberg) while respecting capability constraints.
Why does this separation matter? Agents should reason about business logic (logical layer) while the harness handles infrastructure complexity (physical layer). This division produces higher quality results by keeping agent context focused on the problem domain.
Comprehensive Validation
Validation operates continuously throughout the development lifecycle:
- Compile-time: Schema consistency, type safety, semantic correctness
- Plan-time: Physical feasibility, capability matching, optimization validity
- Test-time: Functional correctness against known inputs and expected outputs
- Deploy-time: Configuration validity, resource availability, dependency satisfaction
- Run-time: Data quality assertions, SLA monitoring, anomaly detection
Each validation stage produces structured feedback that agents consume for iterative refinement. The harness transforms validation failures into actionable guidance.
Real-World Feedback
Static validation catches many issues but can't substitute for execution feedback. The harness provides two mechanisms for real-world validation:
Simulation: Execute pipelines locally with timestamp-accurate event replay. The simulator runs the complete stack (Flink, Kafka, Postgres) in Docker, enabling agents to test against realistic data volumes and timing scenarios. Crucially, simulation is deterministic: the same inputs always produce the same outputs, enabling reliable regression testing.
Production Telemetry: Monitor deployed pipelines and correlate observations back to source code. When latency increases or data quality degrades, the harness links metrics to specific transformations, enabling autonomous troubleshooting.
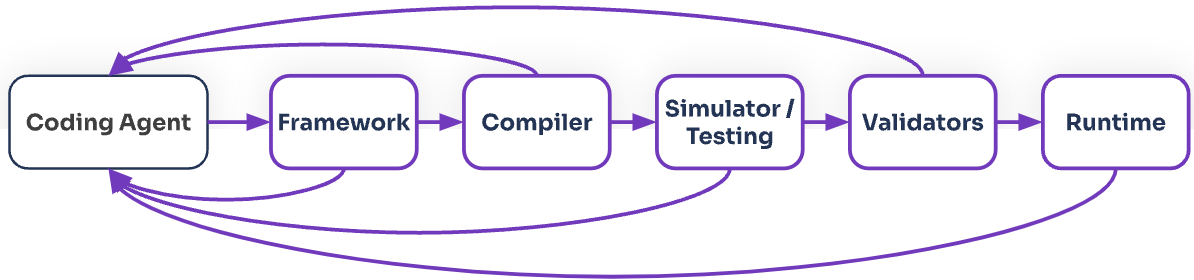
Implementation: The DataSQRL Approach
DataSQRL implements this harness architecture as an open-source framework. Here's how the abstract governance principles translate to concrete tooling.
SQL as the Logical Layer
DataSQRL uses SQRL as the logical representation, which is SQL extended with stream processing from Flink SQL and interface definitions. Why SQL?
- LLM familiarity: Most models are extensively trained on SQL
- Human readability: Engineers can verify agent output without learning new syntax
- Mathematical foundation: Relational algebra enables rigorous validation
- Declarative introspection: We can analyze and transform queries programmatically
-- Agent-generated pipeline in SQRL
IMPORT banking_data.*;
-- Deduplicate CDC stream to current state
Accounts := DISTINCT AccountsCDC ON account_id ORDER BY update_time DESC;
-- Enrich transactions with temporal join
SpendingTransactions := SELECT
t.*,
h.name AS creditor_name
FROM Transactions t
JOIN Accounts FOR SYSTEM_TIME AS OF t.tx_time a
ON t.credit_account_id = a.account_id
JOIN AccountHolders FOR SYSTEM_TIME AS OF t.tx_time h
ON a.holder_id = h.holder_id;
-- Define API endpoint
SpendingByAccount(account_id STRING NOT NULL) :=
SELECT * FROM SpendingTransactions
WHERE debit_account_id = :account_id
ORDER BY tx_time DESC;
Deterministic Transpilation
The mapping from logical to physical layer happens through deterministic transpilation, not agent generation. This eliminates an entire class of subtle bugs:
- Schema mismatches between engines
- Incorrect data type coercions
- Missing index structures
- Inconsistent serialization formats
The transpiler generates deployment artifacts (Flink plans, Kafka topics, Postgres schemas, GraphQL models) that are guaranteed consistent with the logical definition. Agents focus on business logic while the harness handles infrastructure integration.
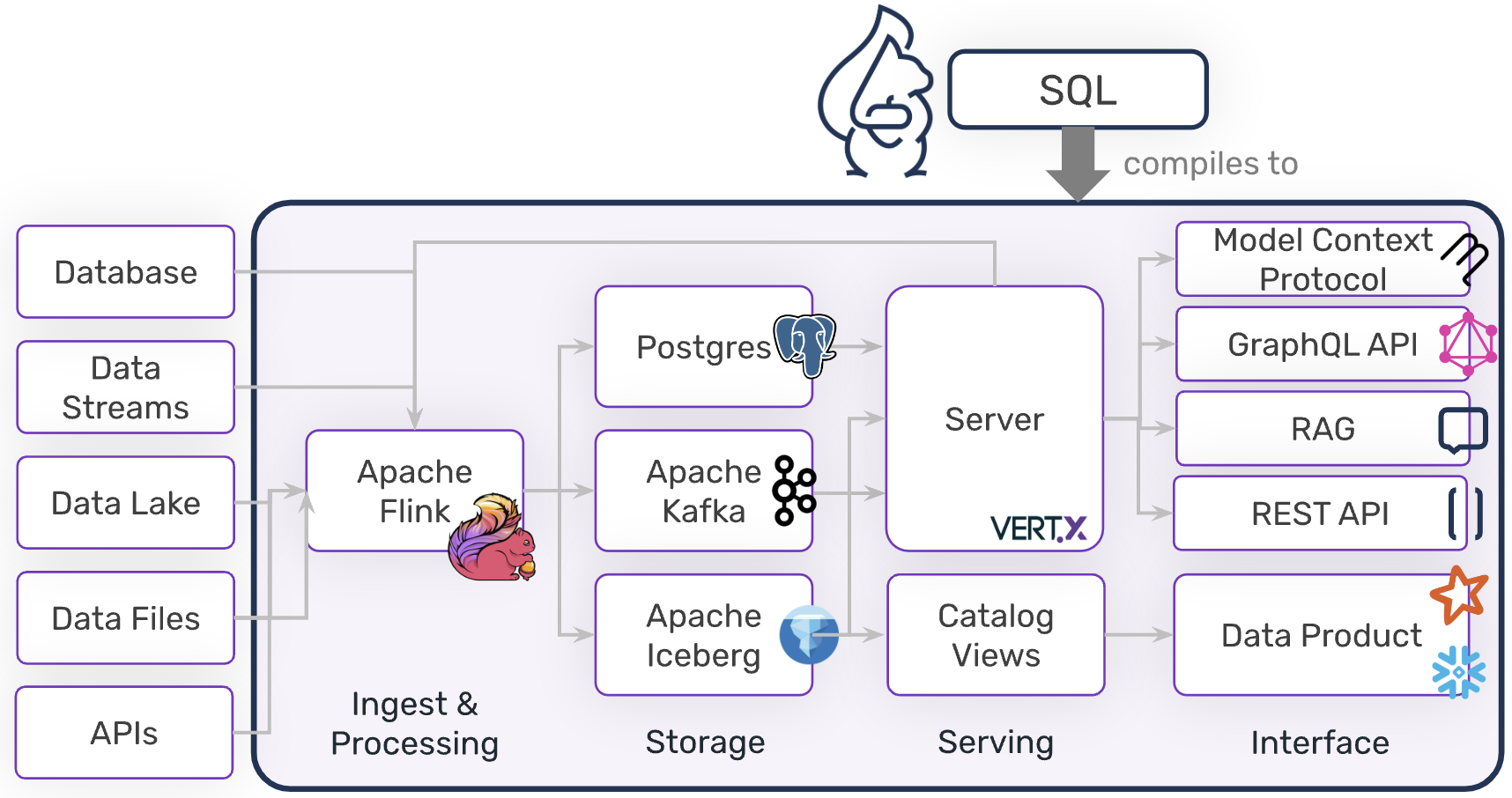
Neuro-Symbolic Optimization
Certain data engineering tasks are better handled by dedicated optimizers than LLM reasoning. DataSQRL implements a neuro-symbolic approach: agents handle high-level design while specialized solvers handle constraint satisfaction.
- Query Optimization: Apache Calcite's Volcano optimizer rewrites queries for performance
- Physical Planning: Cost-based optimizer assigns operations to engines while respecting topological constraints
- Index Selection: Lattice-based optimizer selects index structures that support query access patterns
Agents can provide hints to guide optimization (e.g. forcing specific engine assignments or partition keys) but the optimizer ensures constraint satisfaction. This leverages LLM strengths (reasoning under uncertainty, creative problem-solving) while delegating deterministic optimization to purpose-built systems.
Continuous Evaluation
The harness supports continuous evaluation through automated testing infrastructure:
/*+test */
TransactionEnrichmentTest :=
SELECT creditor_name, COUNT(*) as tx_count
FROM SpendingTransactions
GROUP BY creditor_name
ORDER BY creditor_name;
Test definitions execute against known inputs with expected outputs captured as snapshots. The simulator replays events with precise timestamps, enabling tests for complex scenarios:
- Late-arriving events and watermark handling
- Out-of-order data processing
- Race conditions in temporal joins
- Schema evolution compatibility
Tests provide immediate feedback to agents and spot regressions in CI/CD infrastructure.
Organizational Implications
Successfully integrating AI into data engineering requires organizational adaptation beyond tooling. What shifts as AI assumes greater responsibility for pipeline development?
From Implementation to Oversight
As agents handle routine implementation, data engineers shift focus toward:
- Architecture review: Evaluating agent-proposed designs against organizational patterns
- Pipeline auditing: Reviewing agent-generated pipelines for correctness, efficiency, and compliance
- Domain encoding: Capturing business knowledge in schemas, contracts, and quality rules
- Failure analysis: Investigating production issues and encoding learnings
- Governance evolution: Refining validation rules and operational criteria
This shift parallels the evolution in other engineering disciplines where automation handles routine tasks while humans focus on judgment-intensive decisions.
From Manual Testing to Continuous Validation
Traditional data pipeline testing, manual verification against sample datasets, can't scale with AI-accelerated development. Organizations need to invest in:
- Comprehensive test suites that encode expected behavior across edge cases
- Automated regression detection that flags behavioral changes between versions
- Production monitoring that validates data quality continuously
- Anomaly detection that identifies novel failure modes
The testing burden shifts from per-deployment verification to continuous infrastructure maintenance.
From Tribal Knowledge to Encoded Expertise
AI agents can't access knowledge that exists only in engineers' heads. Organizations need to systematically externalize:
- Data domain semantics and business rules
- Operational patterns and anti-patterns
- Historical failure modes and resolutions
- Consumer requirements and SLAs
This documentation effort has value beyond AI enablement: it improves onboarding, reduces key-person dependencies, and creates institutional memory that persists through team changes.
The Path Forward
AI-assisted data engineering is here. Organizations that successfully integrate AI into their data platforms will achieve significant productivity gains while maintaining the reliability that production systems demand.
AI integration requires infrastructure, not just tools. Coding agents operating without guardrails produce pipelines that work in demos but fail in production. Agents operating within a purpose-built harness with comprehensive validation, real-world feedback, and encoded expertise produce pipelines that meet production requirements.
The data engineering harness represents this infrastructure: a system that provides the governance, validation, and feedback loops necessary for AI-assisted data platform automation.
DataSQRL implements this harness as an open-source framework. You can customize it to encode your domain knowledge, integrate your validation rules, and build an automated data platform tailored to your requirements.
The question is no longer whether AI will transform data engineering, but how we adapt our practices, tooling, and teams to harness its potential while maintaining the trust that data consumers depend on.
Getting Started
To explore AI-assisted data engineering with DataSQRL:
- Build a project from scratch to understand harness components
- Explore example projects demonstrating common patterns
- Read about the harness architecture for detailed technical background
- Contribute to the open-source project to shape the future of AI-assisted data engineering