Avoiding Duplicate Processing in Flink SQL Streaming Jobs


Flink SQL is a powerful abstraction layer that unifies batch and stream processing over semi-structured data. It extends the widely used SQL language with streaming constructs such as tumbling windows, session windows, and, more recently, process table functions. This enables non-experts in streaming technologies to express complex real-time data processing logic succinctly.
As a result, Flink SQL significantly lowers the barrier to entry for building real-time data systems.
However, developing streaming applications differs fundamentally from traditional SQL query processing. One key difference is that streaming jobs often have multiple sinks populated by a single pipeline, sharing large portions of common data processing logic.
While Flink SQL provides mechanisms to express this concisely—using views and statement sets—in practice, this often results in duplicate processing in the generated job graph.
The Core Problem: Why Duplication Happens
In Flink SQL, each sink maps to its own relational tree. These trees are:
- Optimized individually.
- Combined afterward into a single job graph.
By the time they are merged, the query optimization has introduced subtle difference in the shared data processing which render the subgraph merging ineffective. As a result, common processing logic, such as joins, gets duplicated.
Ironically, common SQL optimization techniques like predicate pushdown and projection pruning can make this worse in streaming contexts. While these optimizations are beneficial in traditional query processing (because they avoid computing unused data), they can fragment pipelines in streaming jobs and prevent subgraph sharing.
Example: Clickstream Enrichment with Two Aggregations
Consider a streaming application that:
- Ingests ad click events.
- Enriches them with ad metadata.
- Produces two separate aggregations.
We perform a temporal join between the clickstream and the ad inventory to enrich each click event with ad metadata.
After enrichment, we compute two aggregations:
- Hourly tumbling window that counts number of clicks per ad category.
- Daily tumbling window that counts clicks per advertiser.
Both results are written to a PostgreSQL database for querying.
Below is a simplified Flink SQL script that implements our clickstream aggregation.
-- Clickstream source
CREATE TABLE Clickstream (
user_id STRING,
event_time TIMESTAMP_LTZ(3) NOT NULL METADATA FROM 'timestamp',
ad_id STRING,
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka', ...
);
-- Ad inventory source
CREATE TABLE AdInventory (
ad_id STRING,
category STRING,
advertiser STRING,
launch_date TIMESTAMP_LTZ(3) NOT NULL METADATA FROM 'timestamp',
PRIMARY KEY (ad_id) NOT ENFORCED,
WATERMARK FOR launch_date AS launch_date - INTERVAL '5' SECOND
) WITH (
'connector' = 'upsert-kafka', ...
);
-- Enrich clickstream with ads
CREATE VIEW EnrichedClicks AS
SELECT
c.user_id,
c.event_time,
c.ad_id,
a.category,
a.advertiser
FROM Clickstream AS c
LEFT JOIN AdInventory FOR SYSTEM_TIME AS OF c.event_time AS a
ON c.ad_id = a.ad_id;
BEGIN STATEMENT SET;
-- Hourly tumbling window: clicks per category
INSERT INTO hourly_category_clicks
SELECT
category,
window_start,
COUNT(*) AS click_count
FROM TABLE(
TUMBLE(
TABLE EnrichedClicks,
DESCRIPTOR(event_time),
INTERVAL '1' HOUR
)
)
GROUP BY
category,
window_start;
-- Daily tumbling window: clicks per advertiser
INSERT INTO daily_advertiser_clicks
SELECT
advertiser,
window_start,
COUNT(*) AS click_count
FROM TABLE(
TUMBLE(
TABLE EnrichedClicks,
DESCRIPTOR(event_time),
INTERVAL '1' DAY
)
)
GROUP BY
advertiser,
window_start;
END;
Why Does this Cause Duplicate Processing?
When running this Flink SQL script, the generated job graph duplicates the temporal join.
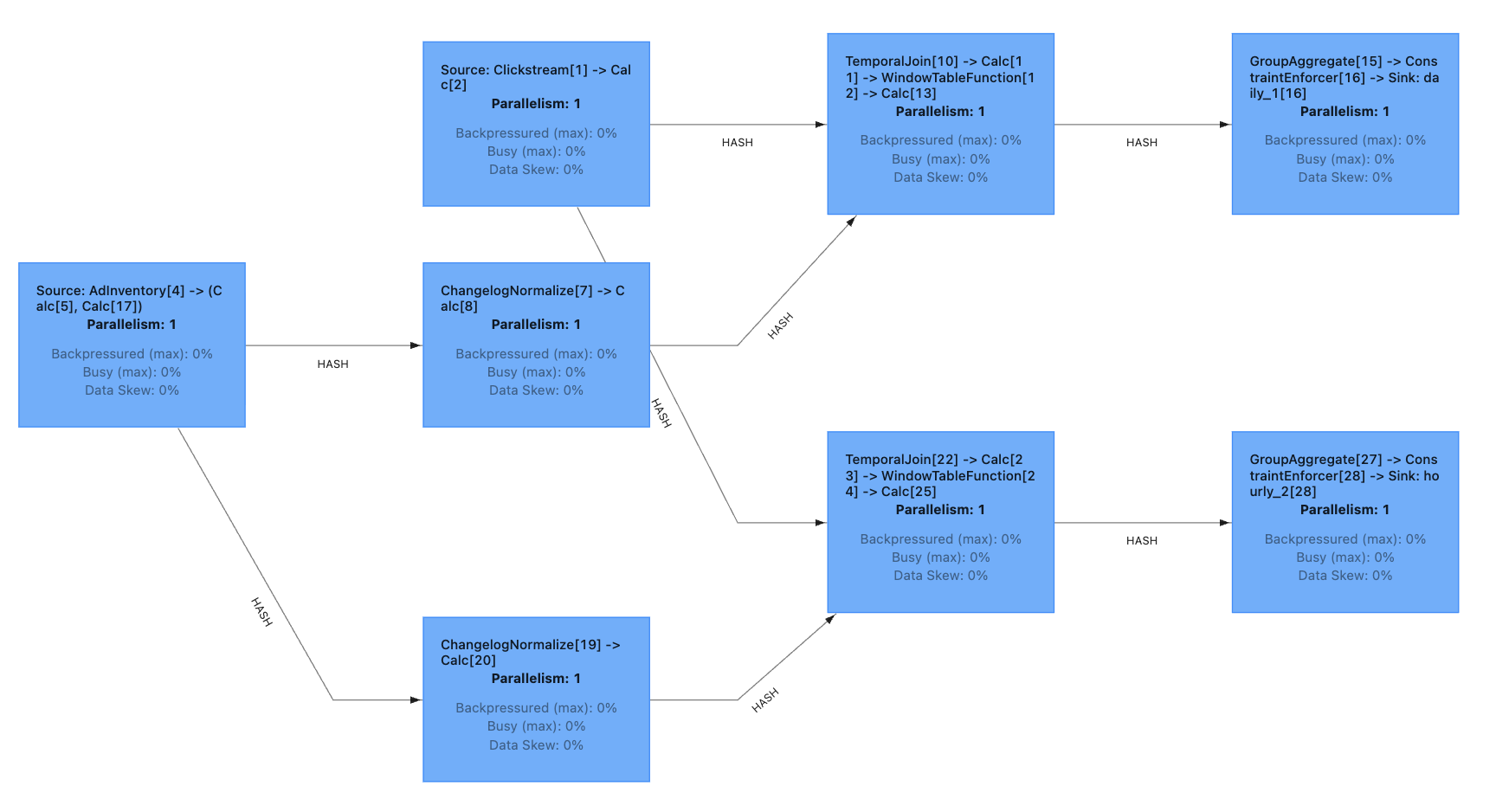
Why? Because the two aggregations needs slightly different data: The hourly aggregation needs category. The daily aggregation needs advertiser. Thus, predicate pushdown and projection pruning cause the optimizer to generate slightly different pipelines for each sink. As a result, the temporal join is executed twice.
In traditional SQL systems, this behavior is desirable because it avoids processing unnecessary fields when you submit a query. In streaming systems, however, this approach is suboptimal because it considers each sink in isolation and not the overall data processing of the entire streaming job.
For our simple application, it is much more efficient to compute the temporal join once and enrich the clickstream with all the ad metadata we need downstream. That eliminates an operator and redundant data processing. More importantly, it cuts the number of state requests to RocksDB in half which is the primary bottleneck for this job.
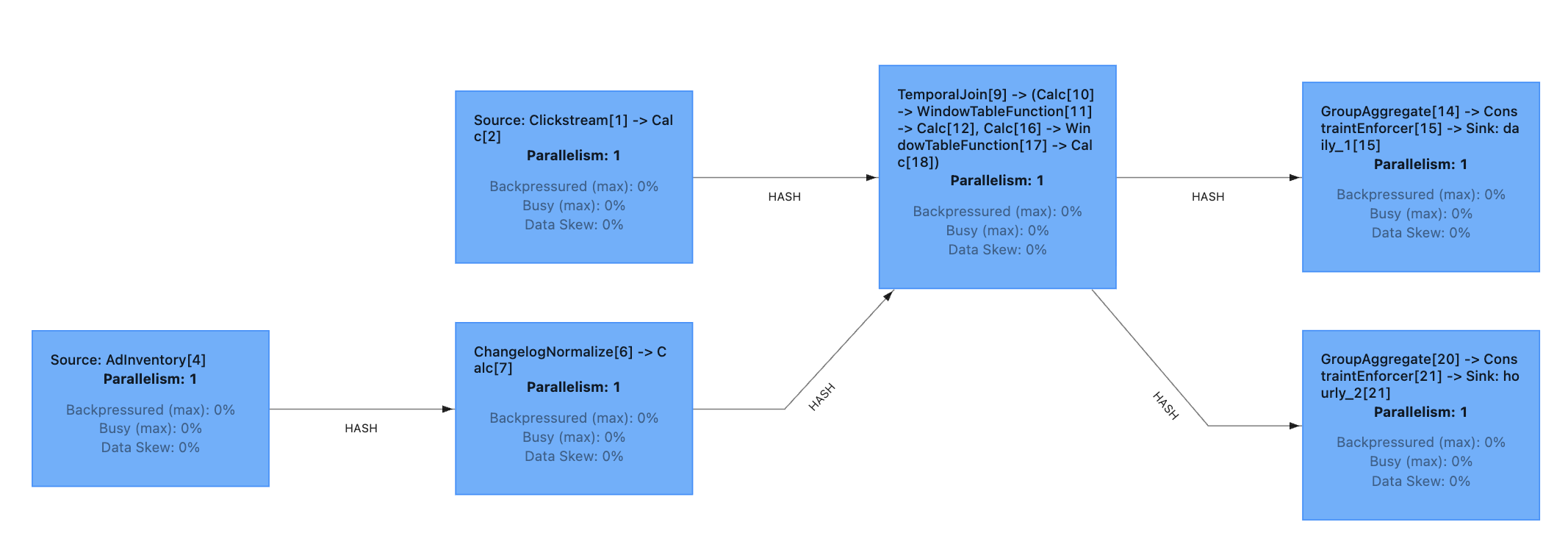
Fixing Job-Graph Duplication in Flink SQL
Apache Flink already provides two important building blocks to eliminate this wasteful duplication:
- Subgraph elimination within the physical
RelNodegraph to remove duplicate processing. - Compile plans, which generate a static artifact representing the generated job graph from Flink SQL.
The compile plan is especially useful because it allows validation of the generated job graph at compile time and assigns stable operator IDs. That's important for job evolution by preserving state mappings across job changes or Flink version upgrades.
Selective Rule Control in Calcite
The issue lies in how the Calcite optimizer applies certain optimization rules, particularly those related to projection pruning and filter pushdown. These are the most likely culprits for causing minor differences in the optimized versions of shared logical plans.
In many real-world streaming scenarios with multiple sinks, these rules prevent effective subgraph elimination because they cause subtle difference in the RelNode graph whereas the subgraph elimination requires strict equality.
The solution is to selectively disable specific Calcite rules so that intermediate views do not get optimized for each RelNode tree and remain identical. Identical RelNode trees are then removed during the subgraph elimination phase of the Flink SQL optimizer.
How Do I use this?
An easy way to remove job graph duplication is to use the DataSQRL compiler and configure the following in your project's package.json:
"compiler": {
"predicate-pushdown-rules": "LIMITED_RULES"
}
This ensures only a limited set of Calcite rules are applied during the compiled plan optimization. DataSQRL is a data automation framework that compiles Flink SQL to data pipelines and it can compile your Flink SQL to a compiled plan with a single command you execute locally. For more information, check out the getting started tutorial.
As an alternative, you can selectively disable Calcite rules in your own instrumentation framework for Flink. Check out this code snippet to see what rules we are disabling. We highly recommend that you produce a compiled plan for your Flink SQL jobs for introspection and predictability. You can use the open-source Flink SQL Runner to execute compiled plans.
In effect, it allows you to define a streaming-specific optimization ruleset, rather than relying solely on optimizations designed primarily for traditional query workloads.
What's Next?
While the ruleset tweaks described above address most cases of subgraph duplication in streaming Flink SQL, we still have some more work to do for certain edge cases.
In particular, SQL constructs that introduce correlation variables (e.g. UNNEST) into the Calcite logical plan do not get deduplicated yet because correlation variable have a static counter that makes each variable unique.
We implemented a normalization algorithm for correlation variables and are looking for ways to contribute it directly to the Apache Flink project.