World Model for Data Platform Automation

DataSQRL is an open-source data automation framework that provides guardrails and feedback for AI coding agents to develop and operate data pipelines, data products, and data APIs autonomously. You can customize DataSQRL as the foundation of your self-driving data platform. Our goal is to develop DataSQRL into a comprehensive world model for data platform automation.
Why DataSQRL?
To understand why you need DataSQRL, let's start with the obvious question: Aren’t LLM-based coding agents good enough?
LLMs are powerful pattern-matching systems but lack grounded models of how data systems behave. Research such as Apple’s 2024 paper “The Illusion of Thinking” shows that LLMs struggle with causal, temporal, and systems-level reasoning, which are the capabilities required to design reliable, multi-engine data pipelines. As a result, agents often generate brittle transformations, invalid mappings, and incorrect assumptions about how data moves and evolves over time.
That is why DataSQRL exists. Coding agents are impressive solution generators, but they require a conceptual framework, validator, and simulator to ensure correctness, safety, and robustness. In most successful agentic systems deployed in the wild, the neural network–driven reasoning is balanced by a set of components that supply structure, constraints, and feedback loops. Collectively, these components are called "World Model".
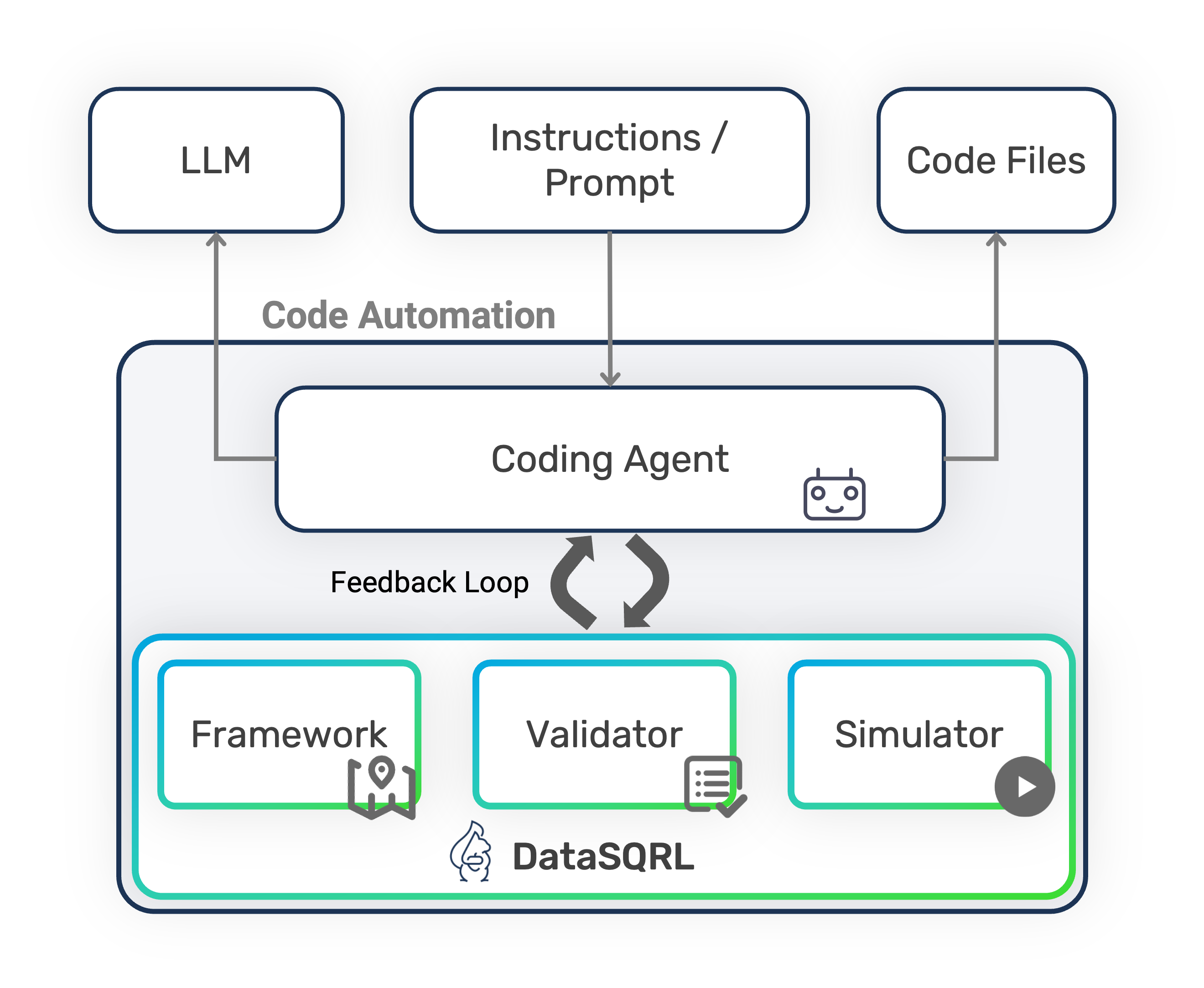
Consider self-driving cars as an example. Neural networks power environmental perception: recognizing lanes, traffic lights, pedestrians. Autonomous driving becomes possible only when this probabilistic perception is grounded in detailed maps, constraint systems, planning modules, and a conceptual framework based on physics and real‑world dynamics.
The neural network alone cannot infer the rules of the road or the relationships that make a driving environment coherent. It needs a world model for driving.
DataSQRL plays that grounding role for coding agents in the context of data platforms and data pipelines.
Let's look at the individual components of DataSQRL to understand how it provides that grounding for AI by building a world model for data processing.
Conceptual Framework
For the purposes of automating data platforms, a comprehensive conceptual framework captures data schemas, data processing, and data serving to consumers. Specifically, we are building a conceptual framework for non-transactional data processing and serving.
The conceptual framework provides the frame of reference for implementing safe, reliable data processing systems. It captures the knowledge from Database Systems: The Complete Book combined with 25 years of data engineering experience.
DataSQRL breaks the framework into logical and physical models.
Logical Model
The logical model expresses what data transformations are needed to produce the desired results.
An obvious choice for the logical model is Codd's relational model and its most popular implementation SQL.
The relational model is widely adopted, proven, and provides a solid mathematical foundation. Most LLMs are trained on lots of SQL code and related documentation. And it is easy for humans to read. Modern versions of SQL (e.g., the SQL:2023 standard) support semi-structured data (JSON), polymorphic table functions, and complex pattern matching to address the messy reality of data platforms.
While the relational model and SQL are a good starting point, we need two additions to achieve the expressibility that modern data platforms require.
1. Dataflow
The relational model uses set semantics. That is inconvenient for representing data flows which are important for data pipelines.
Jennifer Widom's Continuous Query Language extends the relational model with data streams and relational operators for moving between streams and sets.
Flink SQL, based on Apache Calcite, is the most widely adopted implementation of this extended relational model. That's why we use Flink SQL as the basis of the logical model in DataSQRL.
Using a declarative language for the conceptual framework has a number of advantages from concise representation to deep introspection, but a practical shortcoming is the fact that some data transformations are easier to express imperatively. Flink SQL overcomes this by supporting user defined functions and custom table operators in programming languages like Java. This gives us a logical model grounded in relational algebra with flexible extensibility to express complex data transformations imperatively.
DataSQRL builds on Flink SQL and adds 1) concise syntax for common transformations, 2) dbt-style templating, and 3) modular file management and importing. These features help with context management for LLMs by reducing the size of the active context that needs to be maintained during implementation and refinement.
-- Ingest data from connected systems
IMPORT banking_data.AccountHoldersCDC; -- CDC stream from masterdata
IMPORT banking_data.AccountsCDC; -- CDC stream from database
IMPORT banking_data.Transactions; -- Kafka topic for transactions
-- Convert the CDC stream of updates to the most recent version
Accounts := DISTINCT AccountsCDC ON account_id ORDER BY update_time DESC;
AccountHolders := DISTINCT AccountHoldersCDC ON holder_id ORDER BY update_time DESC;
-- Enrich debit transactions with creditor information using time-consistent join
SpendingTransactions :=
SELECT
t.*,
h.name AS creditor_name,
h.type AS creditor_type
FROM Transactions t
JOIN Accounts FOR SYSTEM_TIME AS OF t.tx_time a
ON t.credit_account_id = a.account_id
JOIN AccountHolders FOR SYSTEM_TIME AS OF t.tx_time h
ON a.holder_id = h.holder_id;
We call this SQL dialect SQRL. You can read the documentation for a complete reference of the SQRL language.
2. Serving
In addition to data processing, a critical function of data platforms is serving data to consumers as data streams, datasets, or data APIs. Data APIs, in particular, are becoming more important with the rise of operational analytics and MCP (Model Context Protocol) for making data accessible to AI agents.
To support data serving, DataSQRL adds support for endpoint definitions via table functions and explicit relationships.
Table functions are part of the SQL:2016 standard and return entire tables as result sets computed dynamically based on provided parameters. In DataSQRL, table functions can be defined as API entry points.
/** Retrieve spending transactions within the given time-range.
from_time (inclusive) and to_time (exclusive) must be RFC-3339 compliant date time.
*/
SpendingTransactionsByTime(
account_id STRING NOT NULL METADATA FROM 'auth.accountId',
from_time TIMESTAMP NOT NULL,
to_time TIMESTAMP NOT NULL
) :=
SELECT * FROM SpendingTransactions
WHERE debit_account_id = :account_id
AND :from_time <= tx_time
AND :to_time > tx_time
ORDER BY tx_time DESC;
Secondly, DataSQRL allows for explicit relationship definitions between tables which are important for API-based data access where results need to include related entities like most recent orders or recommendations for movie category. The relational model does not support traversing through an entity-relationship model, which is usually handled by an object-relational mapping layer when exposing an API. To avoid that extra complexity and impedance mismatch in our logical model, DataSQRL provides first-class support for relationships.
-- Create a relationship between holder and accounts filtered by status
AccountHolders.accounts(status STRING) :=
SELECT * FROM Accounts a
WHERE a.holder_id = this.holder_id
AND a.status = :status
ORDER BY a.account_type ASC;
With the addition of access functions and relationships, the logical model maps directly to the entity-relationship model of GraphQL which DataSQRL uses as the logical model for API-based data retrieval. This gives DataSQRL a highly expressive interface with a simple extension of the logical model which retains conceptual simplicity of the framework.
The interface documentation provides more details on the serving layer of DataSQRL.
Physical Model
The physical model represents how the data gets processed and served. It's a translation of the logical model into executable code that runs on actual data systems.
Pipeline Architecture
With hundreds of database systems and many more data infrastructure choices, it is a daunting challenge to construct a simple and coherent physical model that is flexible enough to cover the diverse needs of data platforms.
After analyzing a wide range of data platforms, we identified that the vast majority of implementations combine multiple data systems from these categories:
- Database: for storing and querying data, e.g., PostgreSQL, MySQL, SQLServer, Apache Cassandra, Clickhouse, etc.
- Table Formats and Query Engines: For analytic data, separating compute from storage can save money and support multiple consumers. DataSQRL conceptualizes this as a "disintegrated database" with table formats for storage (e.g., Apache Iceberg, DeltaLake, Apache Hudi) and query engines for access (e.g., Apache Spark, Apache Flink, Snowflake).
- Data Processor: for batch or realtime transformation of data, e.g., Apache Spark, Apache Flink, etc.
- Log/Queue: for reliably capturing data and moving it between data systems, e.g., Apache Kafka, RedPanda, Kinesis, etc.
- Server: for capturing and exposing data through an API
- Cache: sits between server and database to speed up frequent queries over less-frequently changing data.
We call each data system an engine and the above categories engine types. When looking at data platform implementations at the level of engine types, we see about 15 patterns emerge (the 10 most popular are documented here) that arrange those engines in a directed-acyclic graph (DAG) of data processing.
Hence, we use a computational DAG that models the flow of data from source to interface as the basis of our physical model. Each node in the DAG represents a logical computation mapped to be executed by an engine. Thus, the physical model provides an integrated view of the entire data flow.

Transpiler
While the physical model gives the AI control over what engine executes which computation, the actual mapping of logical to physical plan is done by a deterministic transpiler built in Apache Calcite. This avoids subtle bugs in data mapping and execution. The results of the transpilation are deployment assets which are executed by each engine. For example, the transpiler generates the database schema and queries for Postgres.
In the transpiler component, we make the following simplifying assumptions:
- The database engines support a version of SQL (e.g., PostgreSQL, T-SQL) or a subset thereof (e.g., Cassandra Query Language)
- The data processor supports a SQL-based dialect (e.g., Spark SQL, Flink SQL)
- The log engine is Apache Kafka compatible (e.g., RedPanda, Azure EventHub)
- The server has a GraphQL execution engine.
This modular architecture allows new engines to be added by conforming to the engine type interface and implementing the transpiler rules in Calcite where needed. At the same time, it abstracts much of the physical plan mapping complexity from the AI, which produces higher quality results and preserves context for higher-level reasoning.
Configuration
DataSQRL uses a package.json file to configure the engines used to execute a data pipeline. The configuration file defines the overall pipeline topology, the individual engine configurations, and the compiler configuration. One file controls how the physical model is derived and executed, making it simple for the AI to experiment with and fine-tune the physical model.
Interface
For the data serving interface, we use GraphQL schema as the physical model which bidirectionally maps to the access functions, table schema, and relationships defined in the logical plan by naming convention. GraphQL fields are mapped to SQL or Kafka queries based on their respective definitions in SQRL. This allows the AI to fine-tune the API within the GraphQL schema.
Furthermore, REST and MCP APIs can be explicitly or implicitly defined through GraphQL operations. Implicit definition traverses the GraphQL schema from root query and mutation fields. Explicitly defined operations are provided as separate GraphQL files.
Using GraphQL as the physical model for the API combines simplicity with flexibility while benefiting from the prevalence of GraphQL in LLM training data.
Validator
The conceptual framework gives AI coding agents a frame of reference to reason about data pipeline and data product implementations. DataSQRL provides validation to support that reasoning and give users tools to ensure the correctness and quality of the generated pipelines and APIs.
Verification & Introspection
Verification and introspection complement the conceptual framework by reinforcing the concepts, rules, and dependencies. DataSQRL provides validation at 3 levels: the logical model, physical model, and deployment assets (the code that gets executed by the engines).
Logical
At the logical level, the DataSQRL compiler verifies syntax, schemas, and data flow semantics. This ensures that the data pipeline is logically coherent and that data integration points (e.g., between the SQL definitions and GraphQL schema) are consistent.
One of the benefits of using relational algebra as the basis for our framework is the ability to run rules and deep traversals over the operators in the relational algebra tree. The DataSQRL compiler uses Apache Calcite's rule and RelNode traversal framework to validate timestamp propagation, infer primary keys and data types, validate table types, and more. This validation component can be extended with custom rules to validate domain-specific semantics and constraints.
The validation component was designed to provide comprehensive context and suggested fixes for validation errors. In our testing, this produces significantly better results compared to the AI coding agent having to look up and reason about encountered errors.
Physical
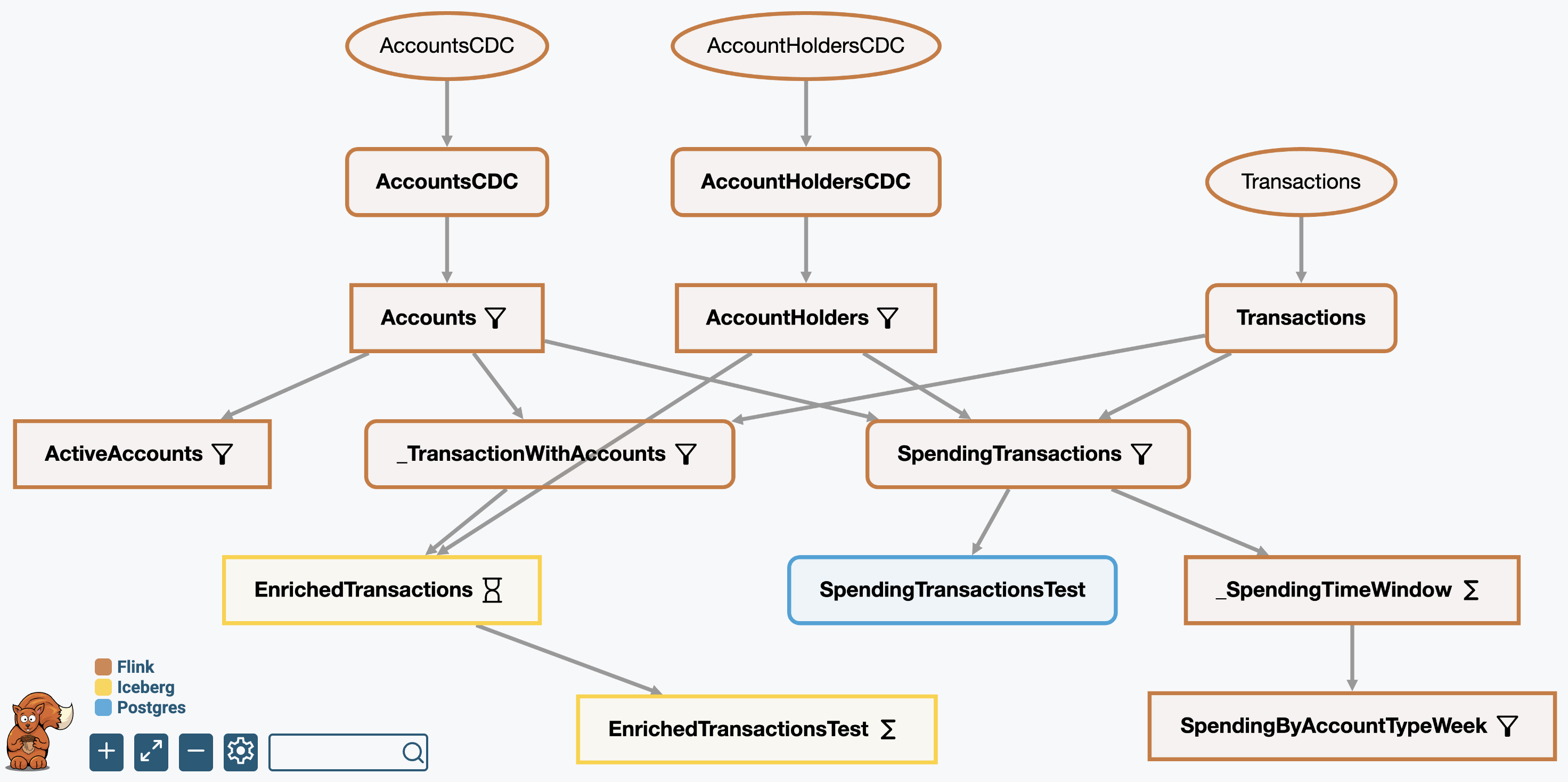
On compilation, DataSQRL produces the computational data flow DAG that represents the physical model. DataSQRL generates a visual representation as shown above for human validation as well as a concise textual representation that is consumed by coding agents as feedback on their proposed solutions and to reinforce the conceptual data flow of the framework.
=== CustomerTransaction
ID: default_catalog.default_database.CustomerTransaction
Type: stream
Stage: flink
Inputs: default_catalog.default_database._CardAssignment, default_catalog.default_database._Merchant, default_catalog.sources.Transaction
Annotations:
- stream-root: Transaction
Primary Key: transactionId, time
Timestamp : time
Schema:
- transactionId: BIGINT NOT NULL
- cardNo: VARCHAR(2147483647) CHARACTER SET "UTF-16LE" NOT NULL
- time: TIMESTAMP_LTZ(3) *ROWTIME* NOT NULL
- amount: DOUBLE NOT NULL
- merchantName: VARCHAR(2147483647) CHARACTER SET "UTF-16LE" NOT NULL
- category: VARCHAR(2147483647) CHARACTER SET "UTF-16LE" NOT NULL
- customerId: BIGINT NOT NULL
This representation of the physical model combines the inferences from the logical model with the mapping to execution engines to provide a source-to-interface definition of the data flow.
Validation at the physical level ensures that data type mappings are consistent and that the engine assignments are valid, i.e., that an assigned engine has the capabilities to execute a particular operator. DataSQRL uses a capabilities component that extracts all requirements from an operator (e.g., temporal join, or a particular function execution) and validates that the engine supports the corresponding capabilities.
Deployment Assets
The executable deployment assets are transpiled from the physical model. Since the transpilation is deterministic, this yields better results than letting the coding agent generate them, and it keeps the conceptual framework concise. However, we generate all deployment assets in a text representation that the coding agent can easily consume as another source of feedback. This is particularly useful during troubleshooting where the deployment assets are the ultimate source of truth of what is being executed and allow the agent to reason "backwards" to the logical model and how to fix it.
Specifically, we generate:
- Database: The database schema, index structures, and (parameterized) SQL queries for all views and API entrypoints.
- Data Processor: The optimized physical plan and compiled execution plan.
- Log: The topic definitions and filter predicates.
- Server: The mapping from GraphQL fields to database or Kafka queries as well as operation definitions. Also, the GraphQL schema if it is not provided.
Optimization
While LLMs' reasoning ability under uncertainty is outstanding, we have found LLMs to perform worse and less consistently on deterministic optimization and constraint satisfaction problems. This finding is supported by a rich body of research in neuro-symbolic AI which researches the integration of neural networks (like LLMs) with symbolic computation (e.g., solvers, planners) and has documented how neural networks alone fall short for such tasks.
DataSQRL follows the neuro-symbolic approach and provides 3 types of planners for deterministic sub-tasks in the implementation and maintenance of data pipelines:
Query Optimization
Query rewriting and optimization is a well-established technique for producing high-performing physical plans from relational algebra. DataSQRL relies on Apache Calcite's Volcano optimizer and HEP rule engine for this purpose.
Physical Planning
The physical plan DAG is subject to a number of constraints forced by the real-world constraints of physical data movement. For example, to serve data on request in the API, the data needs to be available in the database - we cannot serve the data straight from a data processor, for example. These topological constraints combined with the capabilities of individual engines render many AI-proposed solutions invalid.
Hence, we implement a physical planner that uses a cost model with a greedy heuristic to assign logical operators to engines in a way that is consistent. The AI can provide hints to force the assignment of certain operators to specific engines which are added as constraints to the optimizer. This gives the AI control over allocations but shifts the burden of constraint satisfaction to a dedicated solver.
Index Selection
Efficiently querying data in the database or table format requires index structures (or partition + sort keys) that support the access paths to the data. Otherwise, we execute inefficient table scans.
Index structure selection is another optimization problem that is better handled by a dedicated optimizer. We use an adaptation of Ullman et al's lattice framework for data cube selection since data cube selection and index selection are related problems with different optimization functions.
Real World Feedback
A conceptual framework with complementary verification and introspection provides the foundation of a world model for data pipelines with feedback on proposed solutions. However, that feedback is limited to the plan and does not account for the complexities of actual execution. Real-world feedback is critical for iterative refinement of production-grade implementations and troubleshooting issues that arise in operation.
DataSQRL provides two sources of real-world feedback: a simulator that's used at implementation time and telemetry collection from production deployments that captures the operational status of the pipeline.
Simulator
The DataSQRL simulator executes the configured engines with the generated deployment assets within a Docker environment. The simulator can replay events and records at their original timestamp, allowing for deterministic reproducibility of real-world scenarios. This is important for creating realistic test cases as well as reproducing production issues for troubleshooting and regression testing.
By capturing and faithfully replaying records at their original timestamp, the simulator ensures time-consistent semantics of data flows and makes it simple to construct complex test cases for scenarios like race conditions.
Simulation is important in agentic coding workflows because it allows the agent to execute and refine the implementation in a feedback loop that is executed locally and can simulate scenarios that only occur rarely in production.
Read more about invoking the simulator and writing reproducible test cases.
Operations and Telemetry
The most important source of real-world feedback is observing the deployed data pipeline in a production environment (or a closely approximated pre-prod environment). Observability is critical for assessing the health of the pipeline and troubleshooting any issues that may occur.
Logs and telemetry collection is a well-established practice for DevOps. What DataSQRL adds is the ability to link observed data back to the physical computation DAG so the agent can accurately reason about cause and effect. For data pipelines that execute across multiple engines, many complex errors arise at the boundary between systems - e.g., an issue in the data processing causes too many writes to the database which degrades performance - and require reasoning across individual systems. To automate such troubleshooting, we need to correlate observations back to the physical data flow and logical model.
DataSQRL currently assumes production operation in Kubernetes or Docker and provides hooks for extracting logs and telemetry data. Correlating that data back to the physical model is not fully abstracted yet and requires individual setup for each deployment. This is work in progress.
Summary
DataSQRL is a data automation framework that provides the foundational building blocks for autonomous data platforms. DataSQRL provides a world model consisting of a conceptual framework, validator, and real-world simulator. It uses a neuro-symbolic approach for integrating solvers, planners, and transpilers to handle deterministic optimizations, following the principle of keeping the agentic context and task scope narrow to improve accuracy. DataSQRL empowers coding agents with a feedback loop, which enables automation through iterative refinement.
DataSQRL is a flexible framework that can be adapted to multiple data engines and extended for custom verification rules, analyses, and feedback.
DataSQRL is open-source so you can customize it to build a self-driving data platform tailored to your requirements.
Getting Started
To try out DataSQRL:
- Build a project from scratch with DataSQRL to see how the components of DataSQRL work
- Look at example projects and run/modify them locally.
- Read the documentation
- Check out the open-source project on GitHub