Data Pipeline Automation
DataSQRL automates the development of reliable data pipelines in SQL.
Build data APIs or data products, serve data via MCP or RAG.
-- Ingest data from connected systems
IMPORT banking-data.*;
-- Enrich debit transactions with creditor information using time-consistent join
SpendingTransactions :=
SELECT
t.*,
h.name AS creditor_name,
h.type AS creditor_type
FROM Transactions t
JOIN Accounts FOR SYSTEM_TIME AS OF t.tx_time a
ON t.credit_account_id = a.account_id
JOIN AccountHolders FOR SYSTEM_TIME AS OF t.tx_time h
ON a.holder_id = h.holder_id;
-- Create secure MCP tooling endpoint with description for agentic retrieval
/** Retrieve spending transactions within the given time-range.
fromTime (inclusive) and toTime (exclusive) must be RFC-3339 compliant date time.
*/
SpendingTransactionsByTime(
account_id STRING NOT NULL METADATA FROM 'auth.accountId',
fromTime TIMESTAMP NOT NULL,
toTime TIMESTAMP NOT NULL
) :=
SELECT * FROM SpendingTransactions
WHERE debit_account_id = :account_id
AND :fromTime <= tx_time
AND :toTime > tx_time
ORDER BY tx_time DESC;
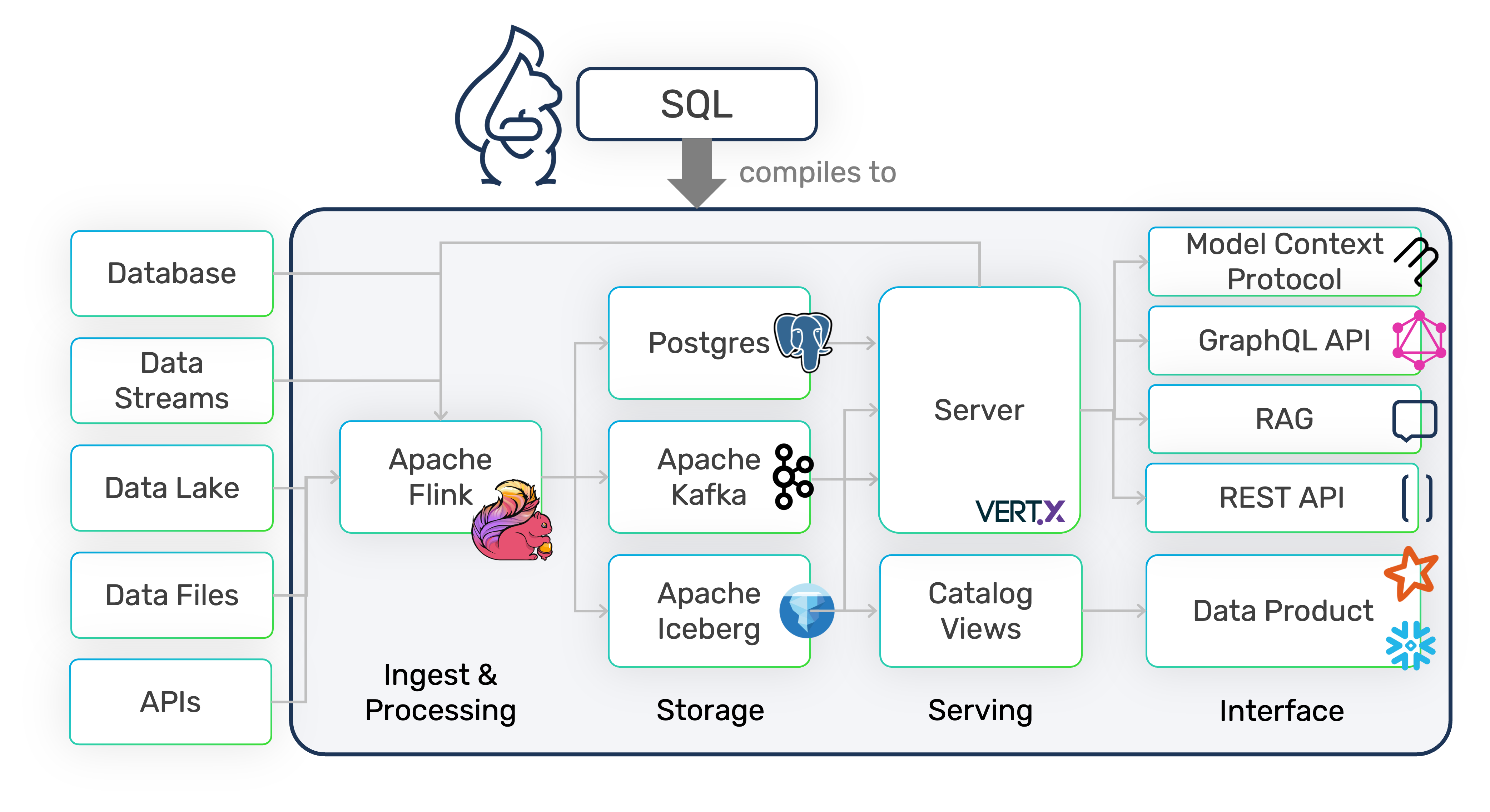
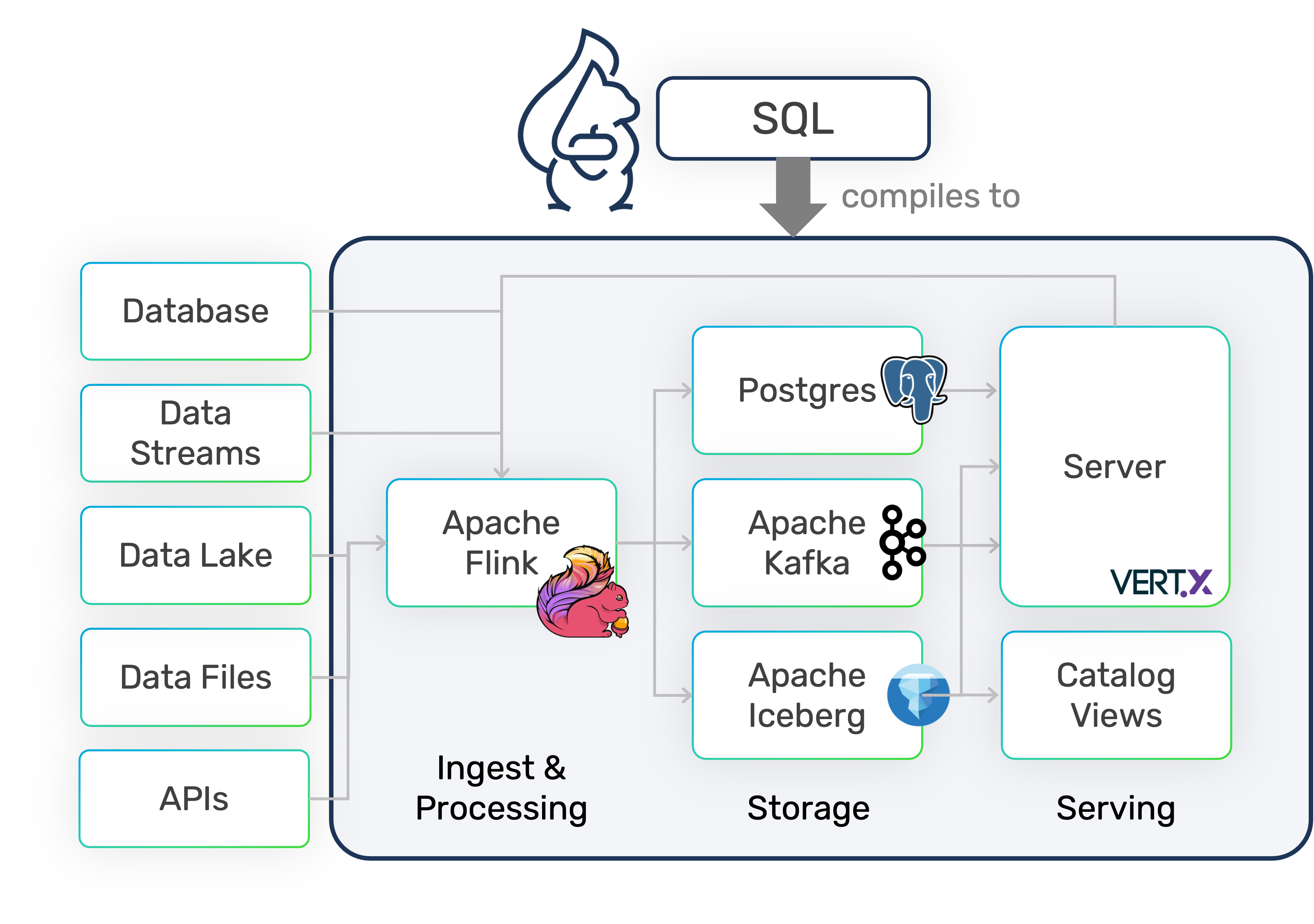
Data Pipeline in a Single SQL Script
DataSQRL compiles declarative SQL into production-ready data pipelines that ingest, process, store, and serve data with built-in testing, observability, and data integrity guarantees.
All in a single SQL script.
DataSQRL automates the data plumbing.
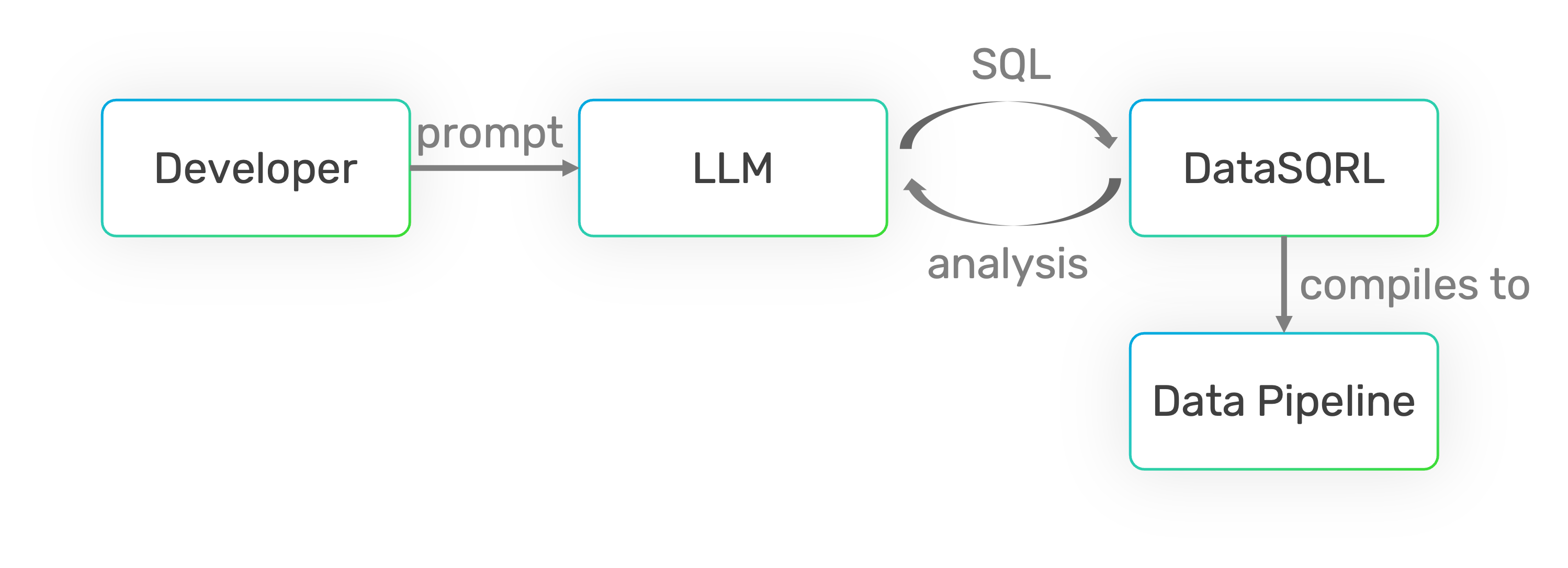
End-to-End Automation with Understanding
SQL can be generated by most LLMs and is easy to understand.
DataSQRL provides the analysis LLMs need to generate quality pipelines iteratively.
Data Consistency and Integrity
DataSQRL compiles SQL to a consistent data pipeline with at-least-once or exactly-once processing guarantees and data integrity validation.
DataSQRL provides complete transparency into the data pipeline artifacts and compile-time verification for results you can trust.
/*+test */
EnrichedTransactionsTest :=
SELECT debit_holder_name,
COUNT(*) AS debit_tx_count,
SUM(amount) AS total_debit_amount
FROM EnrichedTransactions
GROUP BY debit_holder_name ORDER BY debit_holder_name ASC;
Ensure Correctness with Tests
Snapshot tests and assertions ensure correctness and spot regressions in CI/CD.
DataSQRL generates tests with 100% reproducibility.
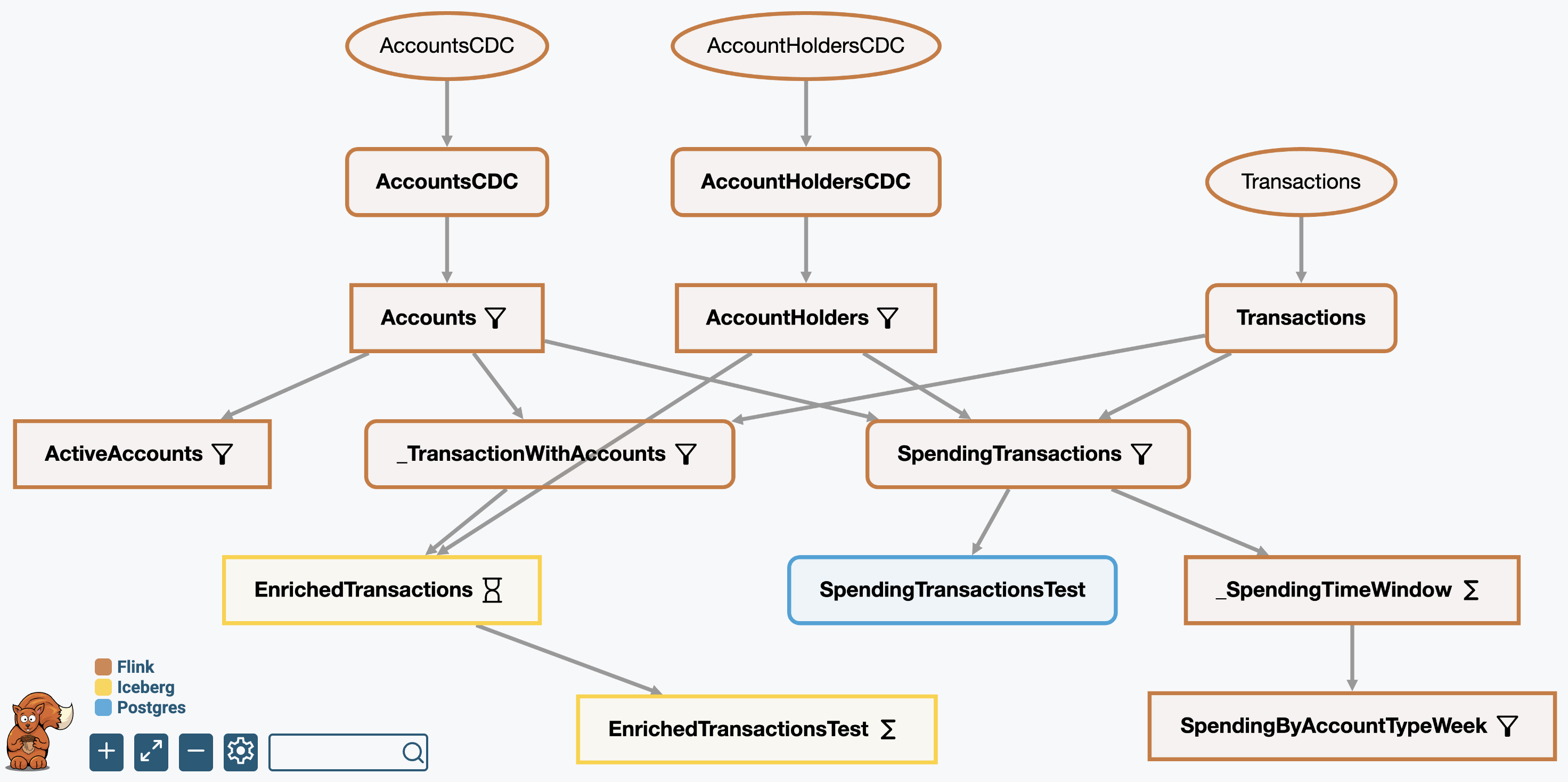
Pipeline Generation and Optimization
DataSQRL optimizes the allocation of pipeline steps to execution engines and generates the integration code with data mappings and schema alignment.
That's a lot of glue code you don't have to write.
IMPORT stdlib.openai.*;
ContentEmbedding :=
SELECT
vector_embedd(text, 'text-embedding-3-small') AS embedding,
completions(concat('Summarize:', text), 'gpt-4o') AS summary
FROM Content;
AI-Native Features
Built-in support for vector embeddings, LLM invocation, and ML model inference.
Use AI features for advanced data processing.
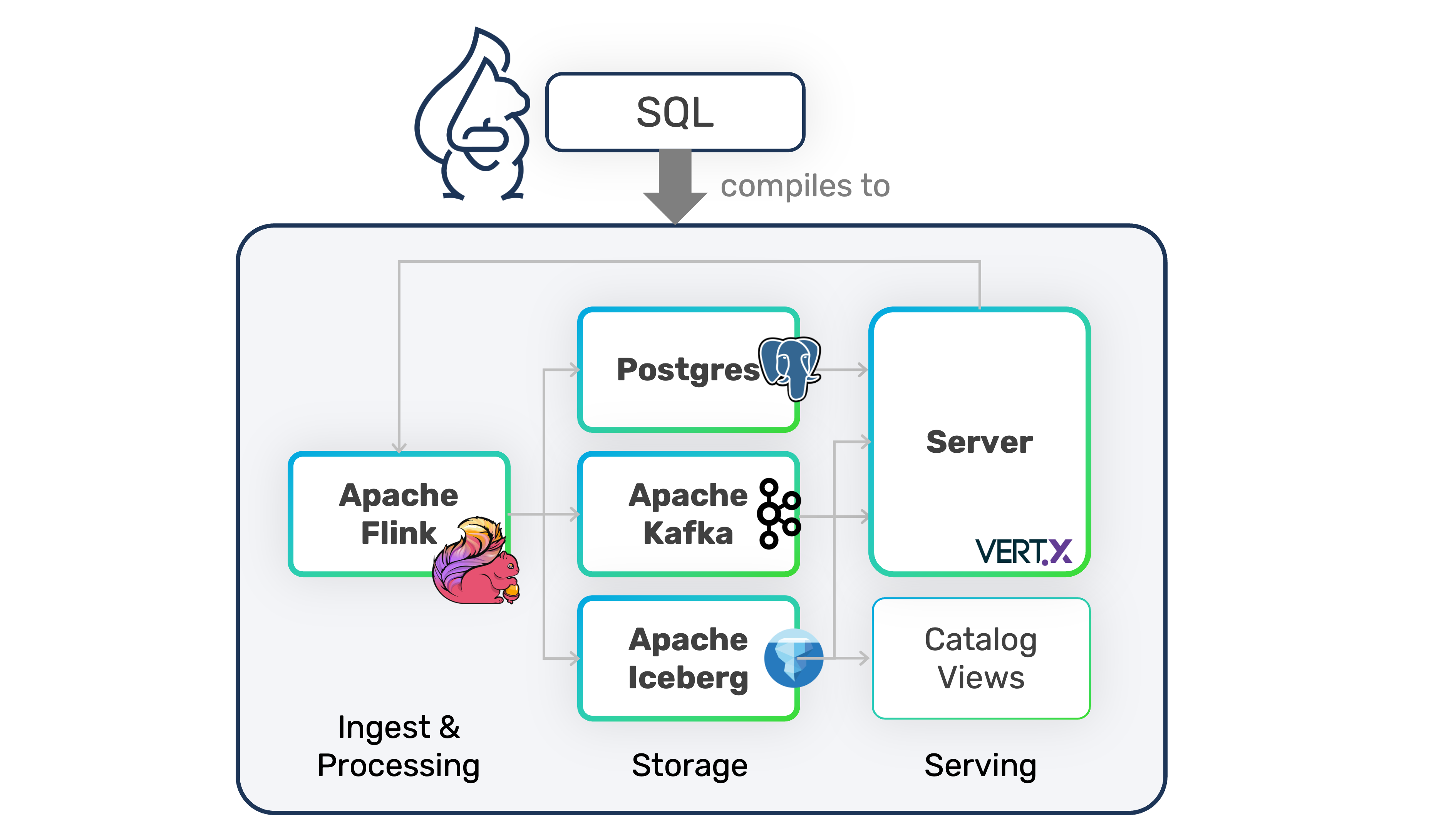
Robust and Scalable
DataSQRL handles partitioning and compiles to proven open-source technologies for runtime execution like Apache Flink, Kafka, and Iceberg that support HA and scale out as needed.
Get operational peace-of-mind and scale when you need to.
-- Create a relationship between holder and accounts
AccountHolders.accounts(status STRING) :=
SELECT * FROM Accounts a
WHERE a.holder_id = this.holder_id AND a.status = :status
ORDER BY a.account_type ASC;
-- Link accounts with spending transactions
Accounts.spendingTransactions(since TIMESTAMP NOT NULL) :=
SELECT * FROM SpendingTransactions t
WHERE t.debit_account_id = this.account_id AND :since <= tx_time
ORDER BY tx_time DESC;
Flexible API Design
Support for table functions and relationships in SQL enable flexible API design for GraphQL, REST, and MCP.
Define data access in SQL and refine the API in GraphQL schema.
Transactions(account_id STRING METADATA FROM 'auth.acct_id') :=
SELECT * FROM SpendingTransactions
WHERE debit_account_id = :account_id
ORDER BY tx_time DESC;
Secure
Use JWT for authentication and fine-grained authorization of data access.
DataSQRL defends against injection attacks.
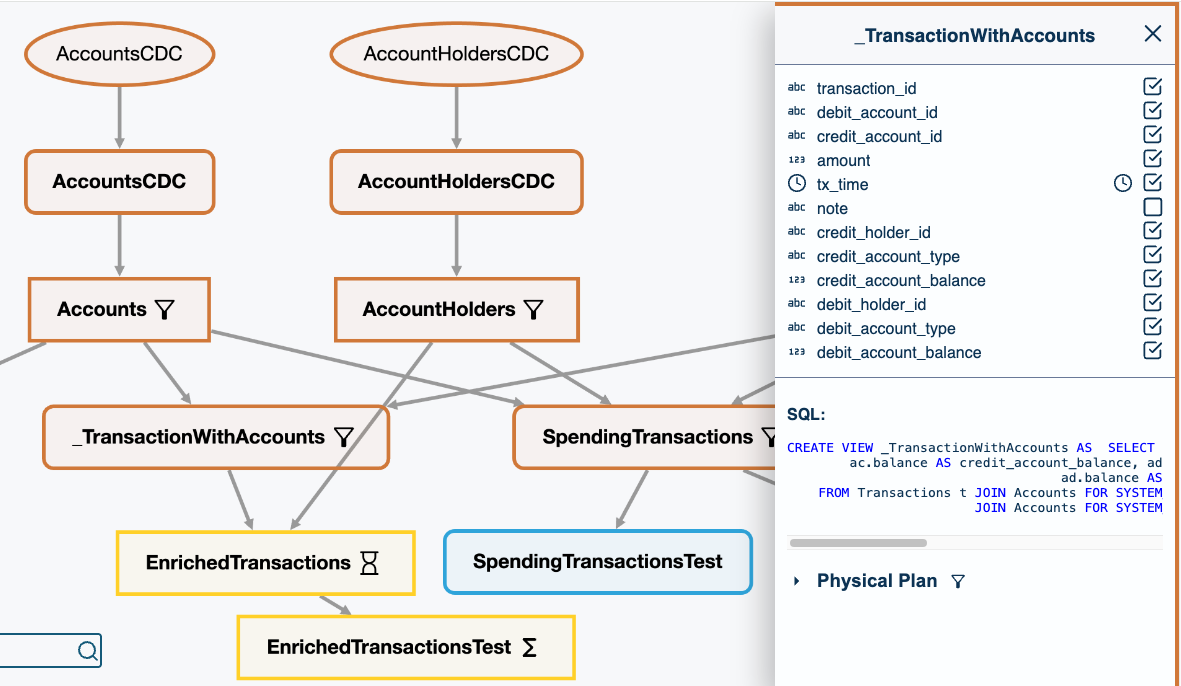
Data Lineage
DataSQRL analyzes the data pipeline and tracks data lineage for full visibility.
Know where the data is coming from and where it's going.
# Run the entire pipeline locally for quick iteration
docker run -it --rm -p 8888:8888 -v $PWD:/build \
datasqrl/cmd run usertokens.sqrl;
# Run test cases locally or in CI/CD
docker run --rm -v $PWD:/build \
datasqrl/cmd test usertokens.sqrl;
# Compile deployment assets to deploy in K8s or cloud
docker run --rm -v $PWD:/build \
datasqrl/cmd compile usertokens.sqrl;
# See compiled plan, schemas, indexes, etc
(cd build/deploy/plan; ls)
Developer Tooling
Local development, automated tests, CI/CD support, pipeline optimization, introspection, debugging.
DataSQRL automates data pipelines within your workflow.

Flexible Deployment
Run locally, in containerized environments (Docker, Kubernetes) and using cloud-managed services.
DataSQRL uses your existing data infrastructure.
CREATE TABLE Transactions (
`timestamp` TIMESTAMP_LTZ(3) NOT NULL METADATA FROM 'timestamp',
WATERMARK FOR `timestamp` AS `timestamp`
) WITH (
'connector' = 'kafka',
'topic' = 'indicators',
'properties.bootstrap.servers' = '${BOOTSTRAP_SERVERS}',
'properties.group.id' = 'mygroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'flexible-json'
);
Connect to Your Data Systems
Connect directly to existing data systems like streaming platforms, databases, or data lakes. Or ingest data through APIs.
DataSQRL simplifies data integration through connector configuration.

Open Source
DataSQRL is licensed under Apache 2 and builds on popular open-source technologies.
Build automation on top of community-driven innovation.
-- Deduplicate an update stream to a stateful table
Accounts := DISTINCT AccountsCDC ON account_id ORDER BY update_time DESC;
-- Join transactions with accounts at the time of the transaction consistently
SpendingTransactions :=
SELECT t.*,
h.name AS creditor_name,
FROM Transactions t JOIN Accounts FOR SYSTEM_TIME AS OF t.tx_time a
ON t.credit_account_id=a.account_id;
-- Aggregate over tumbling time windows
SpendingByWeek := SELECT
account_id,
type,
window_start AS week,
SUM(amount) AS total_spending
FROM TABLE(TUMBLE(
TABLE SpendingTransactions,
DESCRIPTOR(tx_time),
INTERVAL '1' DAY
))
GROUP BY debit_account_id, type, window_start, window_end;
Focus on what Matters
DataSQRL supports time-window aggregations, deduplication, time-consistent joins, and other complex transformations succinctly in SQL.
DataSQRL handles low-level optimizations.
Import custom functions when SQL alone is not enough.
-- Compute enriched transaction to Iceberg with partition
/*+engine(iceberg), partition_key(credit_holder_type) */
EnrichedTransactions := SELECT
t.*,
hc.name AS credit_holder_name,
FROM Transactions t JOIN AccountHolders hc
ON t.credit_holder_id = hc.holder_id;
Full Control
Direct the DataSQRL compiler with hints and configuration for control over pipeline design and execution.
Developer Workflow
DataSQRL integrates into your developer workflow and enables quick iterations.